Effective information searching is essential for enhancing the reasoning and generation capabilities of large language models (LLMs). Recent research has explored using reinforcement learning (RL) to improve LLMs' search capabilities by interacting with live search engines in real-world environments. While these approaches show promising results, they face two major challenges: (1) Uncontrolled Document Quality: The quality of documents returned by search engines is often unpredictable, introducing noise and instability into the training process. (2) Prohibitively High API Costs: RL training requires frequent rollouts, potentially involving hundreds of thousands of search requests, which incur substantial API expenses and severely constrain scalability. To address these challenges, we introduce ZeroSearch, a novel RL framework that incentivizes the capabilities of LLMs to use a real search engine with simulated searches during training. Our approach begins with lightweight supervised fine-tuning to transform the LLM into a retrieval module capable of generating both useful and noisy documents in response to a query. During RL training, we employ a curriculum-based rollout strategy that incrementally degrades the quality of generated documents, progressively eliciting the model’s reasoning ability by exposing it to increasingly challenging retrieval scenarios. Extensive experiments demonstrate that ZeroSearch effectively incentivizes the search capabilities of LLMs using a 3B LLM as the retrieval module. Remarkably, a 7B retrieval module achieves comparable performance to the real search engine, while a 14B retrieval module even surpasses it. Furthermore, it generalizes well across both base and instruction-tuned models of various parameter sizes and is compatible with a wide range of RL algorithms.
🔍 We propose ZeroSearch, a novel reinforcement learning framework that incentivizes the capability of LLMs to use real search engines without interacting with them during training.
🤖 Through supervised fine-tuning, we transform the LLM into a retrieval module capable of generating both useful and noisy documents in response to a query. We further introduce a curriculum rollout mechanism to progressively elicit the model’s reasoning ability by exposing it to increasingly challenging retrieval scenarios.
📊 We conduct extensive experiments on both in-domain and out-of-domain datasets. Results show that ZeroSearch outperforms real search engine-based models while incurring zero API cost. Moreover, it generalizes well across both base and instruction-tuned LLMs of various parameter sizes and supports different reinforcement learning algorithms.
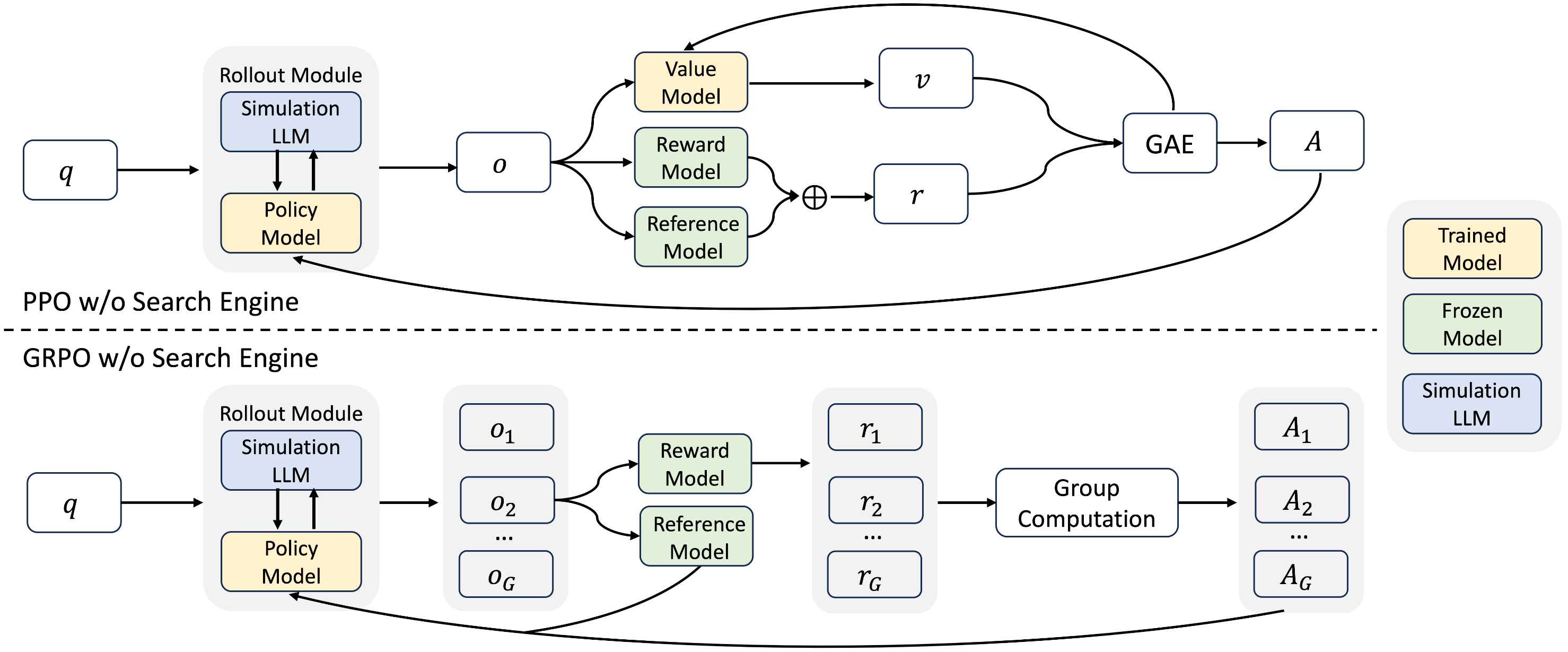
Reinforcement Learning without a Search Engine We propose a reinforcement learning framework that eliminates the need for a real search engine by leveraging an LLM to simulate the search engine. The optimization objective is formulated as:
\[ \max_{\pi_\theta} \mathbb{E}_{x \sim \mathcal{D},\,y \sim \pi_{\theta}(\cdot \mid x; \pi_{\psi})} \bigl[\,r_{\phi}(x, y)\bigr] \;-\;\beta\,\mathrm{D}_{\mathrm{KL}}\bigl[\pi_{\theta}(y \mid x; \pi_{\psi}) \,\big\|\, \pi_{\mathrm{ref}}(y \mid x; \pi_{\psi})\bigr], \]
where \(\pi_{\theta}\) is the policy model to be optimized, \(\pi_{\mathrm{ref}}\) is the reference model, and \(r_{\phi}\) denotes the reward function. \(\pi_{\psi}\) represents the simulation LLM, whose parameters remain fixed throughout training.
Search Simulation Tuning We propose a lightweight supervised fine-tuning (SFT) procedure. Specifically, we first collect interaction trajectories by prompting the LLM to engage with a real search engine in a multi-turn manner until a final answer is reached. From these trajectories, we extract query-document pairs and employ the LLM as the judge to independently assess whether each document contains sufficient information to answer the corresponding query. Then, we perform lightweight SFT to enhance the LLM’s ability to generate both useful and noisy outputs in response to queries.
Rollout with Curriculum Search Simulation During rollout, the policy model performs interactive reasoning and generates search queries, which are fed into the simulation LLM to produce corresponding documents. To gradually increase the difficulty of training, we introduce a curriculum learning-based rollout mechanism, where the quality of the retrieved documents is progressively degraded over time. This is controlled by a probability function \(p_i\) that governs the likelihood of generating noisy documents at step \(i\):
\[ p_i\;=\; p_s \;+\;\frac{b^{\,i/m} - 1}{b - 1}\,(p_e - p_s) \]
Reward Design The reward signal serves as the primary supervision in the reinforcement learning process. In this work, we adopt F1 score-based reward that focuses solely on answer accuracy.
\[ r_{\phi}(x, y) = \frac{2 \times IN}{PN + RN} \]
where IN denotes the number of overlapping words between the prediction and the ground truth, PN is the number of words in the prediction, and RN is the number of words in the ground truth. We do not incorporate an additional reward for output format, as we observed that the model consistently produces well-formed responses without explicit supervision.
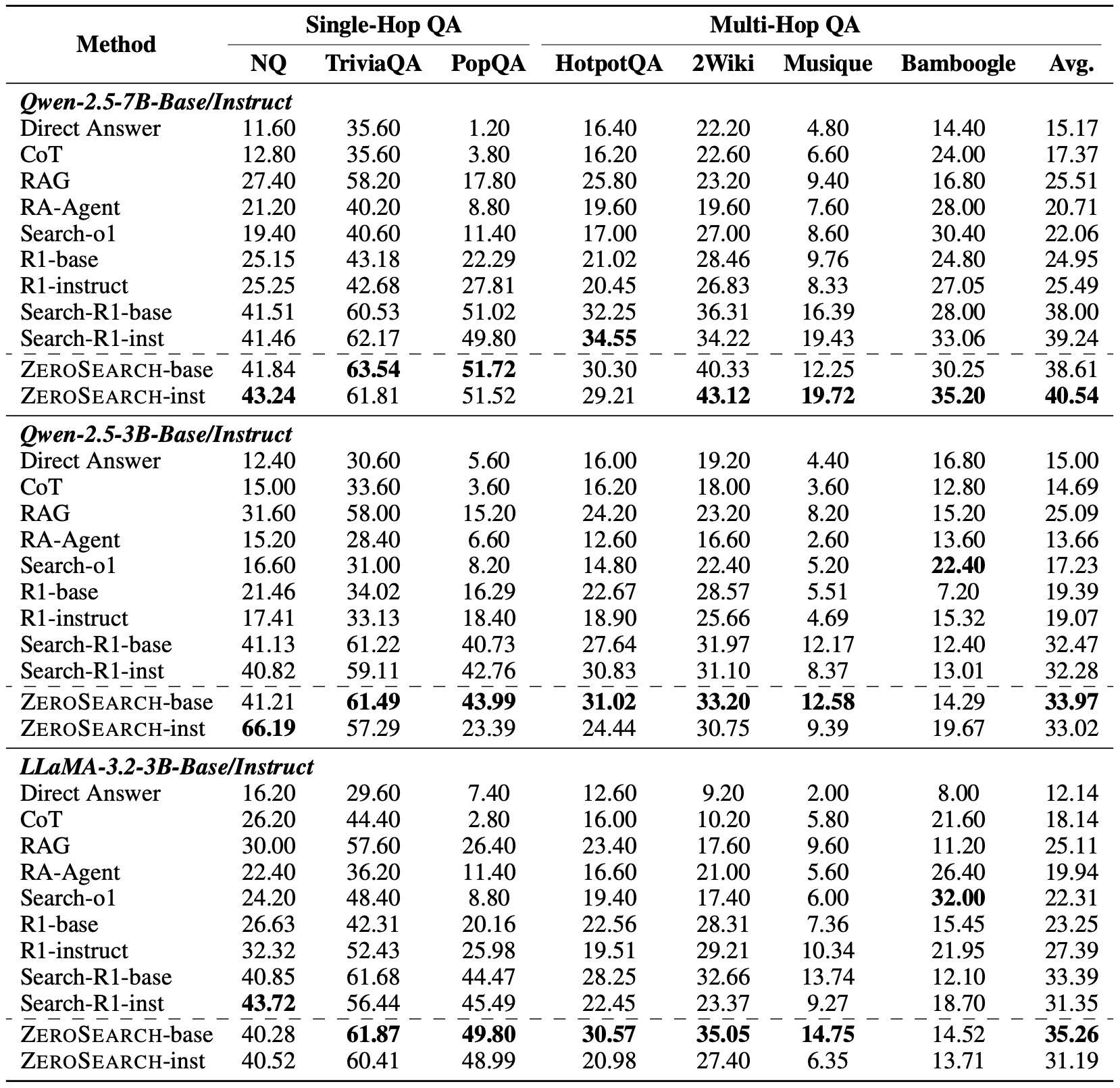
Main Results The above table presents a comparison between ZeroSearch and several baseline methods across seven datasets. Based on the results, several key observations can be drawn:
ZeroSearch consistently outperforms all baseline methods. This performance advantage holds for both in-domain datasets (\textit{i.e.}, NQ and HotpotQA) and out-of-domain datasets (\textit{i.e.}, TriviaQA, PopQA, 2WikiMultiHopQA, Musique, and Bamboogle), demonstrating the robustness of our method.
ZeroSearch surpasses methods that rely on real search engines. Compared to Search-R1, which utilizes a real search engine, ZeroSearch achieves better performance, highlighting its potential as an effective alternative to real search engines in large-scale reinforcement learning.
ZeroSearch demonstrates strong generalizability. Across different model families, sizes, and types (i.e., base or instruction-tuned), ZeroSearch consistently outperforms baselines. Moreover, its performance further improves with larger models, highlighting its scalability.
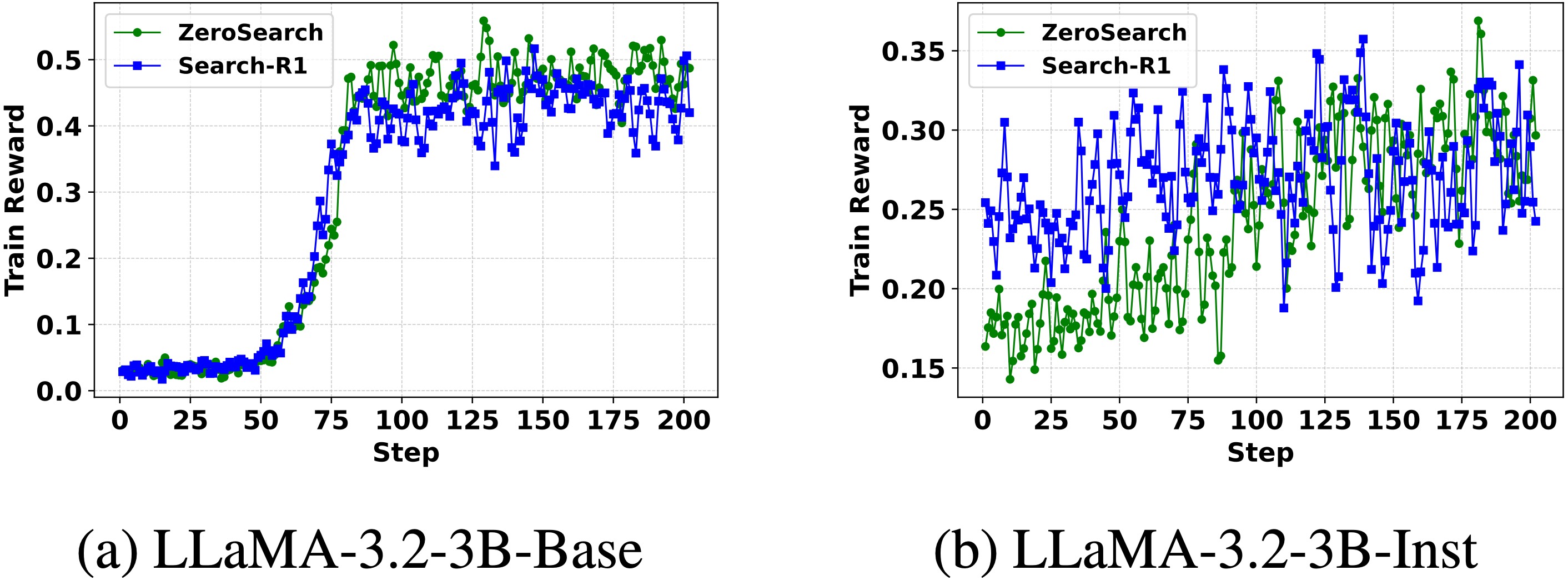
Compare ZeroSearch with Real Search Engine We compare the reward curves of ZeroSearch and Search-R1 (using a real search engine) on LLaMA-3.2-3B.
The overall reward trends are similar across both methods. As training progresses, the reward scores of both ZeroSearch and Search-R1 steadily increase, indicating that the policy models in both settings effectively learn to interact with search engines and produce correct answers.
ZeroSearch achieves a more pronounced reward improvement. ZeroSearch initially lags behind Search-R1 but eventually surpasses it with less fluctuation, thanks to the curriculum mechanism that helps the model gradually master search tool usage.
ZeroSearch generalizes well across both base and instruction-tuned models. Under both model types, ZeroSearch steadily improves reward performance, underscoring its generalizability.
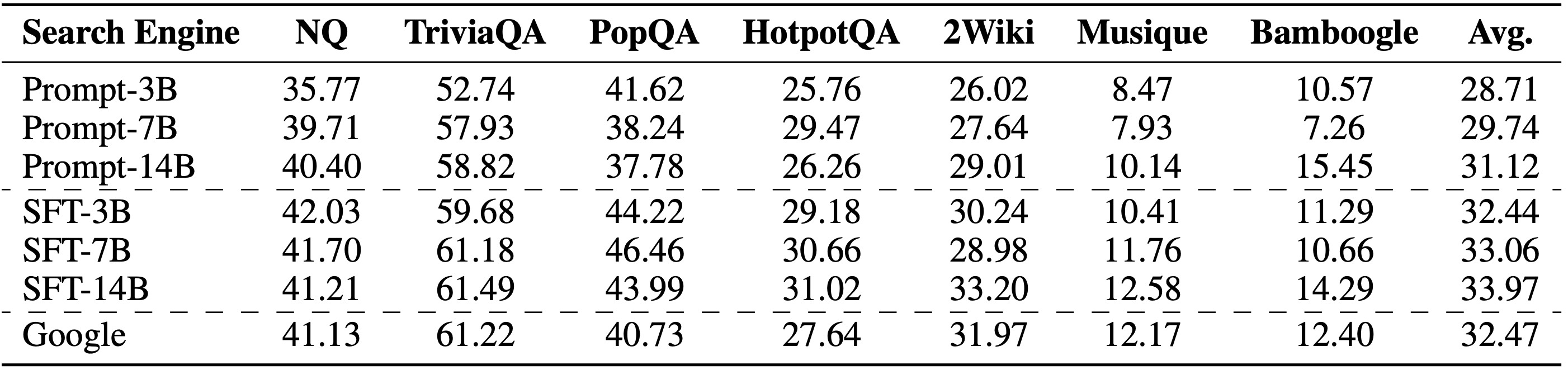
Choice of Simulation LLMs We evaluate how different simulation engine configurations affect performance, including prompt-based and fine-tuned LLMs ranging from 3B to 14B parameters.
The fine-tuned 7B simulation engine (SFT-7B) achieves performance comparable to that of Google Search, while the 14B variant (SFT-14B) even surpasses it. This demonstrates the feasibility of using a well-trained LLM as a substitute for real search engines in reinforcement learning setups.
Fine-tuned (SFT-based) simulation engines significantly outperform prompt-based ones. Although prompt-based methods are explicitly guided to mimic the response style of a real search engine, a substantial distribution gap remains, leading to inferior performance.
Performance improves consistently with increasing model size. Larger simulation LLMs not only exhibit stronger simulation capabilities, but also more accurately distinguish between relevant and irrelevant documents, thereby enabling more effective curriculum learning during training.

Case Study We show several interaction trajectories. From these examples, we observe:
The policy model consistently adheres to the expected output format, even though the format is only specified in the input template and not reinforced by the reward design.
The model demonstrates the capability for multi-turn search behavior to arrive at the final answer. This confirms that our method effectively incentivizes and leverages the model’s search capabilities.
 , Alibaba Group
, Alibaba Group